Kafka adapter with Avro serialization and Schema Registry
Confluent Schema Registry stores Avro schemas for Kafka producer and consumer so that producers write data with a schema that can be read by consumers even as producers and consumers evolve their using schema.
In this post, I am not going to explain what and how those tech terms work in theory. Instead, we will focus on the practical implementation in SAP PO. It’s almost identical to the cloud version of SAP CPI.
Our scenario is every time SAP sends a customer master (DEBMAS) to a third party it will send a copy to Kafka for real-time analytics or act as a middle stream for other apps. We use the Advantco Kafka adapter here.
Schema Evolution
To get up to speed in case you are not familiar with this subject, read the following paragraphs from the Confluent website to understand Avro schema and Confluent Schema Registry.
“An important aspect of data management is schema evolution. After the initial schema is defined, applications may need to evolve it over time. When this happens, it’s critical for the downstream consumers to be able to handle data encoded with both the old and the new schema seamlessly...
When using Avro, one of the most important things is to manage its schemas and consider how those schemas should evolve. Confluent Schema Registry is built for exactly that purpose.”
Prerequisites
Let start by creating Kafka stuff before jumping on the channel configuration.
Create a Kafka topic as the command below, or use any UI tool such as Confluent Control Center to create one.
./bin/kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic debmas07_avroAssume we have an Avro schema ready. If not we can use any online tools to generate one from an XML of the IDOC DEBMAS07 and make some changes if needed. To quickly have an Avro schema for this sample, I just simply use the Advantco Kafka Workbench to convert the XML payload to JSON and then use this online tool to generate an Arvo schema from the JSON.
Use Schema Registry API to upload the Avro schema to the Schema Registry, with a subject name debmas07_avro-value. Or any UI tool such as Advantco Kafka Workbench.
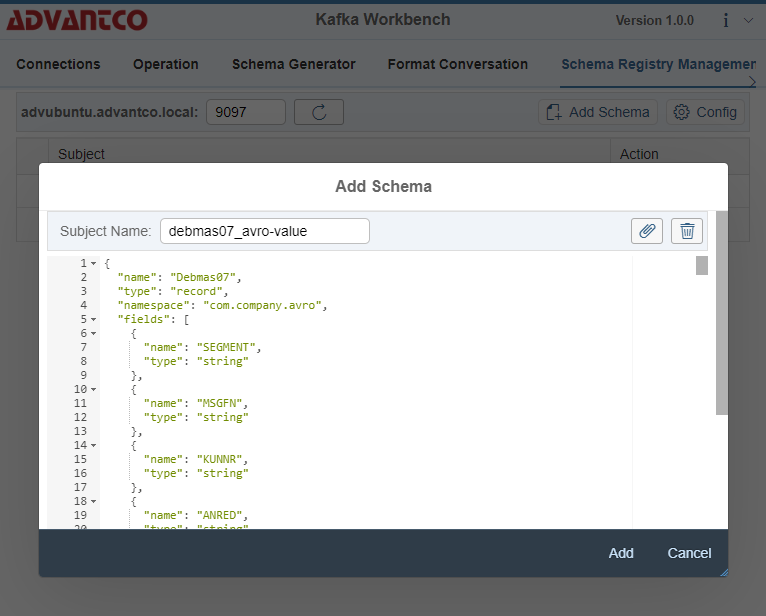
Create a stream from the created topic and schema. It’ll be used later for the real-time queries (KSQL). Run the command below after logging into the KSQL server.
CREATE STREAM sdebmas07_avro \
(KUNNR VARCHAR, \
NAME1 VARCHAR, \
STRAS VARCHAR, \
ORT01 VARCHAR, \
LAND1 VARCHAR) \
WITH (kafka_topic='debmas07_avro', value_format='AVRO', value_avro_schema_full_name='com.company.avro.Debmas07');Producer channel
Assume we have an ICO that SAP sends an IDOC DEBMAS07 to a receiver channel of Kafka adapter.
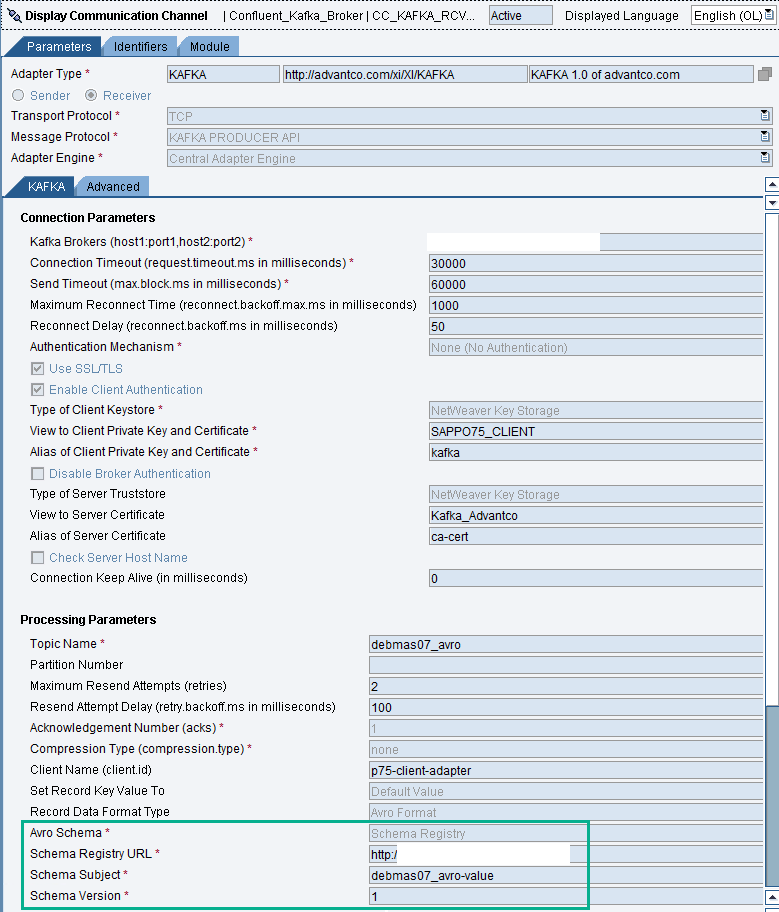
The configuration of the receiver channel to produce messages to the Kafka topic. All messages will be converted to JSON and then serialize to Avro before sending it to Kafka broker. The Avro schema is stored on the Confluent Schema Registry and referencing to a schema by subject name and version.
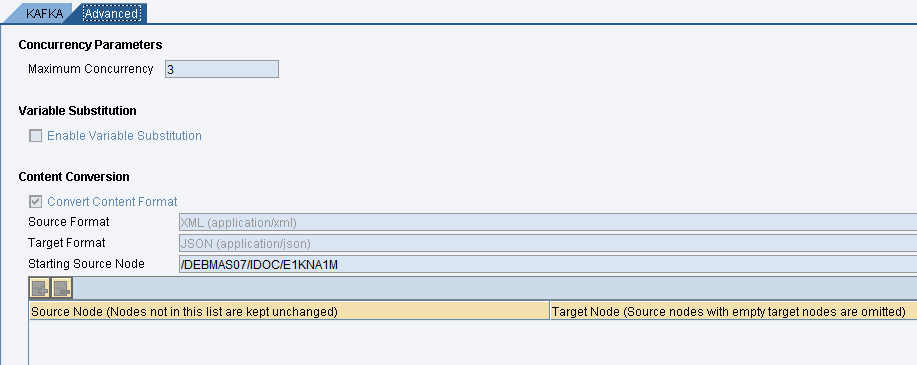
Convert the XML payload to JSON format and store the only segment of E1KNA1M.
Consumer channel
Assume we have another ICO that consumes Kafka messages from the Kafka sender adapter and forward it to a receiver adapter, such as File.
Versions of Arvo schema can be the same or different on the sender and receiver channels. It depends on the Compatibility Type using in the Confluent Schema Registry. Here we use the BACKWARD compatibility type and the new schema version (version 2) to consume messages while the producer is still using the last version (version 1).
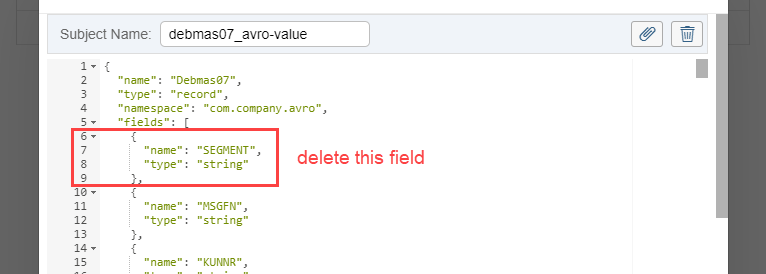
Let make a new version of the schema via the Advantco Kafka Workbench by edit the current version – delete field SEGMENT as the screenshot below and save it. So we have a new version 2 is different from the version 1 only field SEGMENT.
The Kafka sender channel consumes messages from the Kafka topic, it deserializes the message payload from the Avro schema which was used to serialize the message but in a new version.
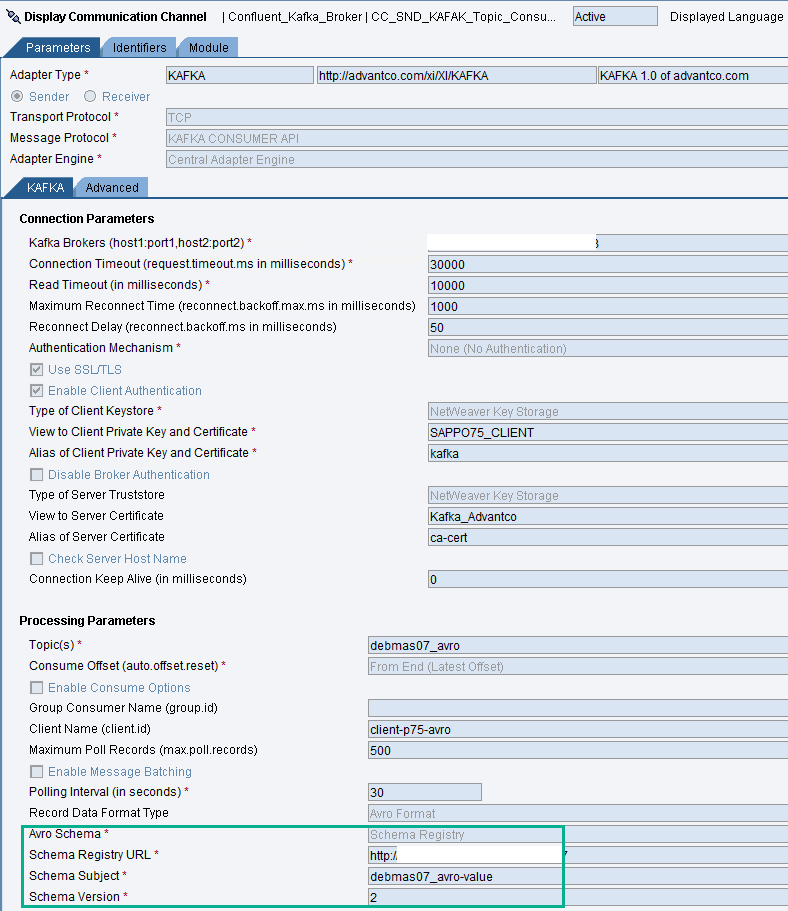
So if we look at the output data of the interface we will not see field “SEGMENT” according to version 2 of the schema.
KSQL channel
KSQL is a stream engine that running SQL statements for Kafka. With powerful provided from KSQL, we easily query data in real-time.
In this example, we are querying customer who is from the US.
Assume we have another ICO that the Kafka sender adapter executes a KSQL query and a File adapter to receive the output.
We already have a stream data pipeline created above, and this is the channel configuration.
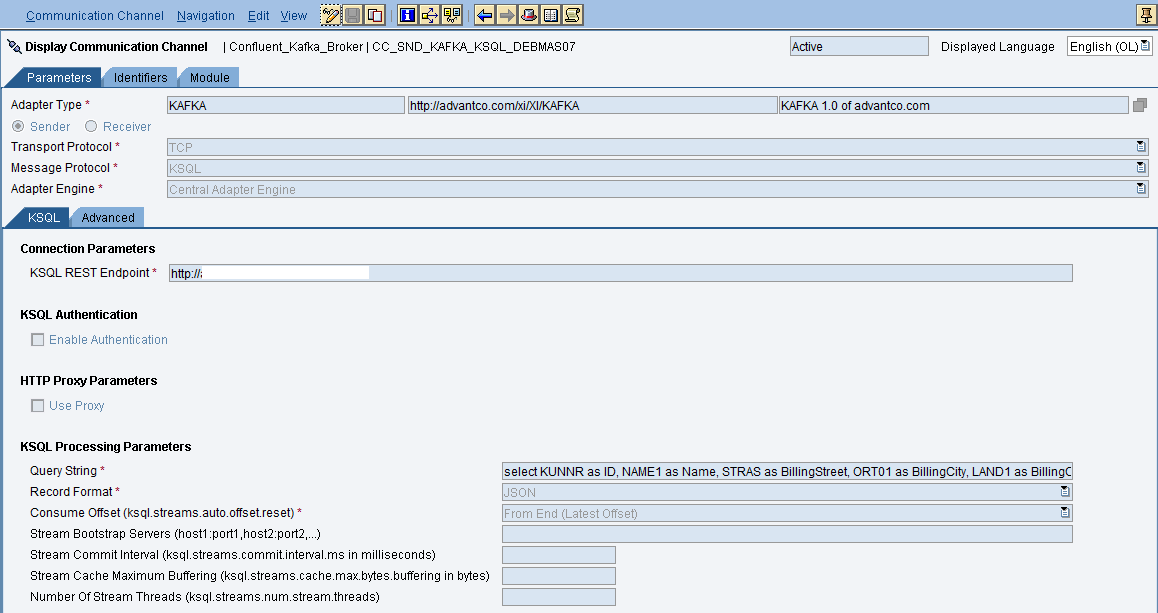
KSQL query.
SELECT KUNNR as ID, NAME1 as Name, STRAS as BillingStreet, ORT01 as BillingCity, LAND1 as BillingCountry FROM sdebmas07_avro WHERE LAND1 = 'US' EMIT CHANGES;We don’t see any Arvo configuration on the channel because the stream sdebmas07_avro (from FROM clause) was created by reading Avro-formatted data.
Conclusion
Avro is a cross-languages serialization of data using a schema. It’s widely used in Kafka to serialize data between apps that developed in different platforms. And with the support from the adapter and the Confluent Schema Registry, we don’t have to write any single line of code to exchange data with other apps, as well as a central place to maintain the schema that developed by a team and reusing by other.
The Advantco Kafka adapter is supporting in two SAP platforms on-prems (PI/PO) and cloud (CPI). There is no difference in functionality.
References
Schema Evolution and Compatibility
https://docs.confluent.io/current/schema-registry/avro.html
Advantco Kafka Adapter
https://www.advantco.com/product/adapter/apache-kafka-adapter-for-sap-netweaver-pipo
Apache Avro
https://avro.apache.org/docs/current/